大數據分析處理:Spark技術、應用與性能優質化[Da Shu Ju Fen Xi Chu Li :Spark Ji Shu 、 Ying Yong Yu Xing Neng...]~推薦!
作者:王家林 ISBN:9789863756231 | |
【Author】作者/繪者/著者/譯者 |
作者簡介
王家林
本書作者王家林在Spark、Hadoop、Android 等方面有豐富的原始程式開發、實務和效能最佳化經驗,徹底研究了Spark 從0.5 到1.1 共18 個版本的Spark 原始程式。
他是Hadoop 原始程式級專家,曾負責某知名公司的類別Hadoop 架構開發工作,專注於提供Hadoop 整合式解決方案,同時也是雲端運算分散式大數據處理的最早實作者之一。
►GO►最新優惠► 【書籍】大數據分析處理:Spark技術、應用與性能優質化
【Introduction】簡介/書評/特色/摘要 |
Hadoop時代來臨之後,雖然已經建立了完整的生態圈,包括儲存、運算,叢集管理以及NoSQL/RDMS等,但這拼圖的最後一個缺角,卻是讓Hadoop人員搥胸頓足的即時處理。Spark的出現,不是淘汰Hadoop,而是讓這個Ecosystem更加完整。
Spark完整的語法、支援Hadoop的MapReduce,再加上特殊的架構以及自有的查詢語言,讓整個大數據圈為之震憾,也打破了Hadoop保持的大數據處理紀錄。如果你是Hadoop的使用者,這本書是你一定要深深研讀,如果你是大數據的新手,這也是你入門的最好選擇。
本書特色
●完全從企業處理大數據夜霧場景的角度出發,利用實際範例的程式碼來組織內容,從零起步,不用任何基礎。
●全書利用Spark框架中核心程式碼解析,掌握Spark實用開發技術,輕鬆駕馭Spark核心和子框架
●於網站附彩色程式碼圖檔供讀者下載、參考
►GO►最新優惠► 【書籍】大數據分析處理:Spark技術、應用與性能優質化
【Table of Contents】目錄/大綱/內容概要 |
ch01 Spark程式設計模型
ch02 建置Spark分散式叢集
ch03 Spark開發環境及其測試
ch04 Spark RDD與程式設計API實戰
ch05 Spark執行模式深入解析
ch06 Spark核心解析
ch07 GraphX大規模圖型計算與圖型擷取實戰
ch08 Spark SQL原理與實戰
ch09 Machine Learning on spark
ch10 Tachyon檔案系統
ch11 Spark Streaming原理與實戰
ch12 Spark多語言程式設計
ch13 R語言的分散式程式設計之SparkR
ch14 Spark效能最佳化和最佳做法
ch15 Spark原始程式解析
附錄A 動手實戰Scala三部曲
►GO►最新優惠► 【書籍】大數據分析處理:Spark技術、應用與性能優質化
【Preface】序/前言/推薦/心得 |
序
誕生於柏克萊大學AMPLab 的Spark 是當今大數據領域最活躍、最熱門、效率最高的大數據通用計算平台。以RDD 為核心,Spark 成功地建置起了一體化、多元化為基礎的大數據處理系統。在任何規模的資料計算中,Spark 在效能和擴充性上都更具優勢。攜帶先天學術基因優勢的Spark在整個發展過程中都深深地具備了學術研究的基因,在「One Stack to rule them all」思想的領導下,Spark 成功地使用Spark SQL、Spark Streaming、MLlib、GraphX 近乎完美地解決了大數據中的Batch Processing、Streaming Processing、Ad-hoc Query 等三大核心問題。在「Full Stack」理想的指引下,Spark 中的Spark SQL、Spark Streaming、MLLib、GraphX 四大子架構和函數庫之間可以無縫地共用資料和操作,這不僅打造了Spark 在當今大數據計算領域其他計算架構都無可匹敵的優勢,而且使得Spark 正在加速成為大數據處理中心首選計算平台。
為什麼寫作本書
Spark + Hadoop = A Winning Combination!
Hadoop 和Spark 聯合組成了當今的大數據世界,而這個世界正在悄悄發生變化,這種變化是Hadoop 負責資料儲存和資源管理,Spark 負責一體化、多元化的不同規模的資料計算,而計算正是大數據的精髓之所在!
在Spark 官方公佈的世界上明確在實際生產環境中使用Spark 的公司可見https://cwiki. apache.org/confluence/display/SPARK/Powered +By+Spark。
在實際的生產環境中,世界上已經出現很多一千個以上節點的Spark 叢集,以eBay 為例,eBay 的Spark 叢集節點已經超過2000 個,Yahoo! 等公司也在大規模地使用Spark,擁有巨大使用者的中國大家的淘寶、騰訊、百度、網易、京東、華為、大眾點評、優酷土豆等也在生產環境下深度使用Spark。2014 Spark Summit 上的資訊顯示,Spark 已經獲得世界20 家頂級公司的支援,這些公司中包含Intel、IBM 等,同時更重要的是,最大的4 個Hadoop 發行商都提供了對Spark 非常強有力的支援。
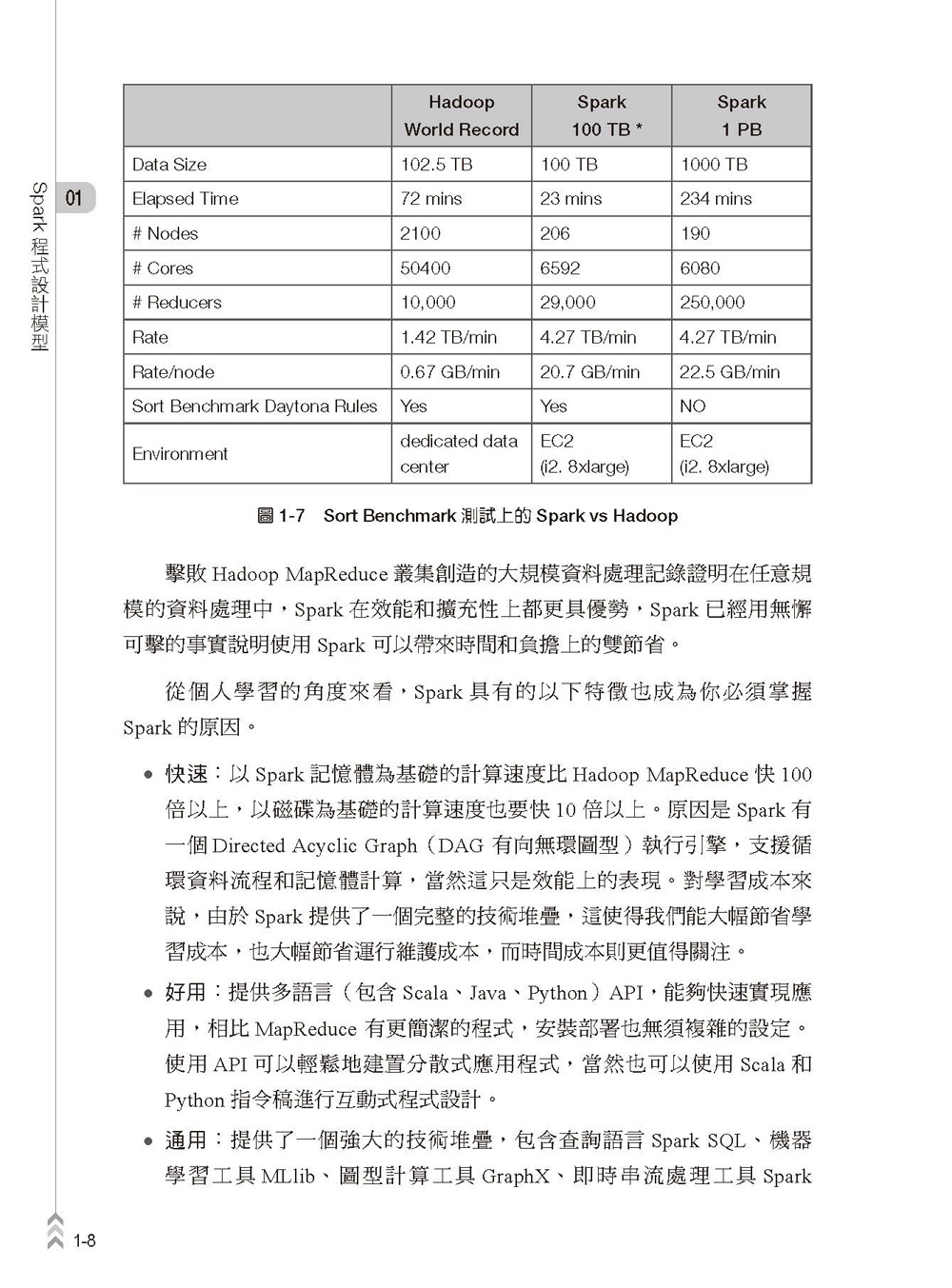
不得不提的是,DataBricks 和AWS 聯合所做的Sort Benchmark 測試表明,Spark 在只用Hadoop 1/10 的運算資源且以磁碟計算為基礎的情況下卻只用了1/3 的運算時間,徹底顛覆了Hadoop 保持的排序記錄,成為開放原始碼軟體領域在TB 和PB 數量級別排序最快的計算引擎。這表明在任意大小的資料規模下,Spark 在效能和擴充性上都更具優勢。
與Spark 火爆程度形成鮮明比較的是Spark 人才的嚴重缺乏,這一情況在華語地區尤其嚴重,這種人才的缺乏一方面是由於Spark 技術在2013、2014 年才開始流行,另一方面是由於缺乏Spark 相關的中文資料和系統化的教育訓練。
本書以最新的Spark 1.1 版本撰寫,本著從企業級實際開發需要的Spark 技能的角度出發,全面說明了Spark 叢集的動手建置、Spark 架構、核心的深入解析、Spark 四大子架構的細緻剖析和實戰、Tachyon 檔案系統揭秘、Spark 多語言程式設計、SparkR、Spark 效能最佳化和最佳做法、Spark 核心原始程式解析等內容。考慮到Spark 架構和開發語言使用Scala,而很多朋友可能對Scala 不是太熟悉,所以在本書的附錄中加入了動手實戰Scala 三部曲來幫助沒有使用過Scala 語言的學習者快速掌握Scala 程式設計。對一名大數據同好來說,本書內容可以幫助他們整合式地完成從零起步到進行Spark 企業級開發所需要的全部核心內容和實戰方法。
►GO►最新優惠► 【書籍】大數據分析處理:Spark技術、應用與性能優質化
ISBN:9789863756231
規格:平裝/880頁/17x23cm/普通級/單色印刷/初版
出版地:台灣
本書分類:電腦資訊>網路/架站>其他網路技術
►GO►最新優惠► 【書籍】大數據分析處理:Spark技術、應用與性能優質化
【Preview】內容預覽/連載/試閱PDF下載 |













ISBN:9789863756231
規格:平裝/880頁/17x23cm/普通級/單色印刷/初版
出版地:台灣
本書分類:電腦資訊>網路/架站>其他網路技術
►GO►最新優惠► 【書籍】大數據分析處理:Spark技術、應用與性能優質化
資料來源:[博客來BOOKS網路書店] http://www.books.com.tw/exep/assp.php/ap/products/0010706206?utm_source=ap&utm_medium=ap-books&utm_content=recommend
圖文屬原創所有。相關資訊僅供參考,歡迎前往選購。發現不妥處請告知!
【Customers Who Bought This Item Also Bought】買的人,也買了... |











沒有留言:
張貼留言